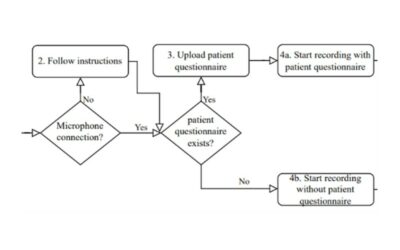
Customized medical prompts enable Large Language Models (LLM) to effectively address medical dialogue summarization. The process of medical reporting is often time-consuming for healthcare professionals. Implementing medical dialogue summarization techniques presents a viable solution to alleviate this time constraint by generating automated medical reports. The effectiveness of LLMs in this process is significantly influenced by the formulation of the prompt, which plays a crucial role in determining the quality and relevance of the generated reports. In this research, we used a combination of two distinct prompting strategies, known as shot prompting and pattern prompting to enhance the performance of automated medical reporting. The evaluation of the automated medical reports is carried out using the ROUGE score and a human evaluation with the help of an expert panel. The two-shot prompting approach in combination with scope and domain context outperforms other methods and achieves the highest score when compared to the human reference set by a general practitioner. However, the automated reports are approximately twice as long as the human references, due to the addition of both redundant and relevant statements that are added to the report.
DOWNLOAD THE PUBLICATION HERE IN PDF:
![]()